


课程描述
Web Scraping in Nodejs & JavaScript 是一个面向项目的网络抓取培训课程,使用 Nodejs 和 JavaScript 以及 Craiglist、iMDB、AirBnB 等真实网站。在本课程中,您将学习如何在 JavaScript Nodejs Request、Cheerio、NightmareJs 和 Puppeteer 的帮助下,使用实际示例和真实站点来抓取网站。
在本课程中,您将学习如何为软件工程工作抓取 Craigslist 网站。您还可以使用 NighmareJs 和 Puppeteer 从需要 JavaScript 的更高级网站(例如 iMDB 和 AirBnB)提取信息。 .
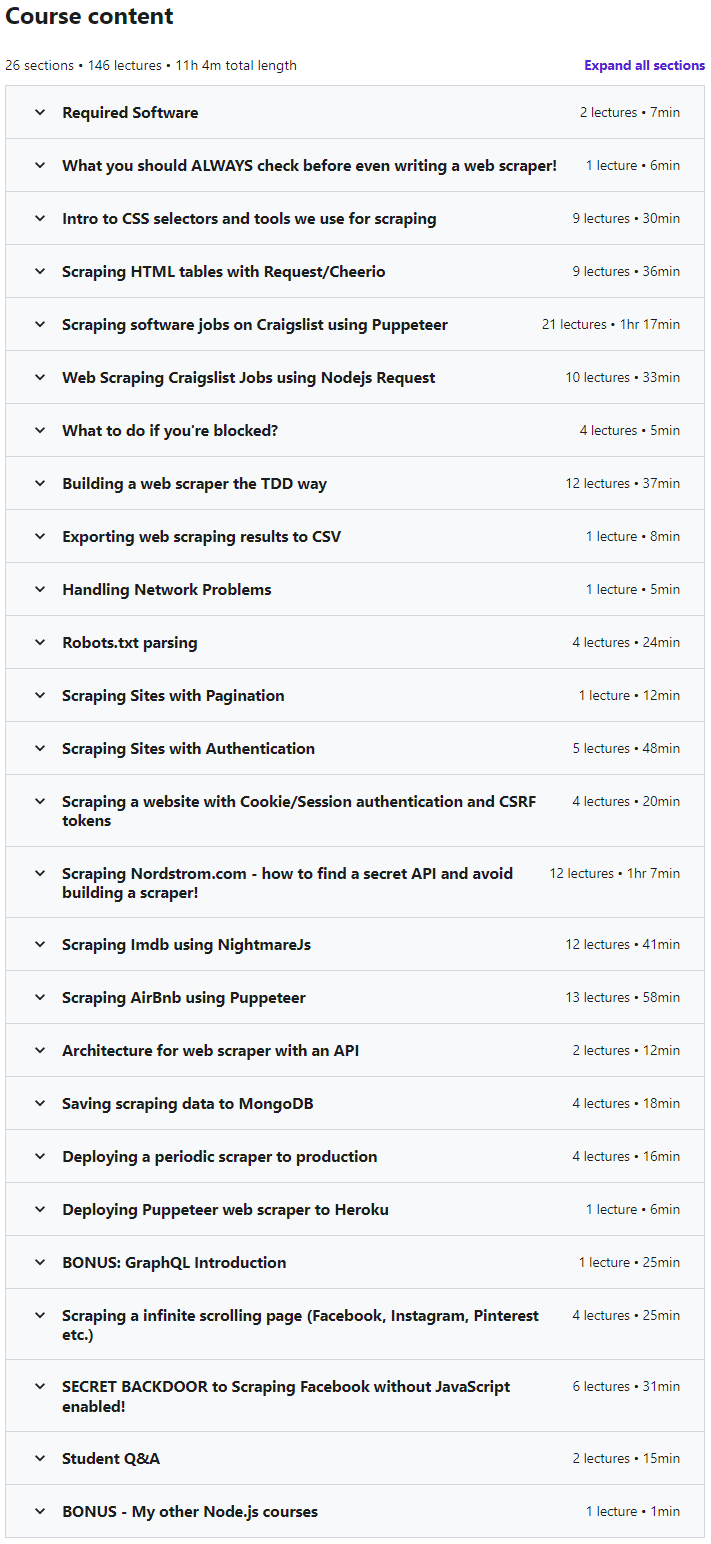
您将在 Nodejs 和 JavaScript 中的网页抓取中学到什么:
- 在 Craigslist 的页面上抓取
- 如何使用请求命令
- 如何使用 NightmareJS
- 如何使用人偶
- 如何抓取没有任何可识别类或 ID 的元素
- 以 CSV 格式保存抓取数据
- 以 MongoDb 格式保存抓取数据
- 如何仅使用请求来抓取 Facebook
- 如何对站点进行逆向工程并找到隐藏的 API
- 了解用于抓取的不同技术
课程规格
出版商:Udemy 讲师:Stefan Hyltoft 语言:英语水平:入门到高级课程数量:146 课时:11 小时 1 分钟
2021/9 课程主题:
课程先决条件:
图片
样片
媒体错误:格式不受支持或来源未找到
安装指南
在 Extract 之后,用您最喜欢的播放器观看。
英文字幕
画质:720p
变化:
与2020/12相比,2021/8版本增加了1节课和3分钟的时长。
声明:本站所有文章,如无特殊说明或标注,均为本站发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。



