教程演示🔗
你会学到什么
-
了解用于特征选择的过滤、嵌入和包装方法
-
了解用于特征选择的混合方法
-
使用套索和决策树选择特征
-
用Python实现不同的特征选择方法
-
了解为什么少(功能)多
-
减少数据集中的特征空间
-
构建更简单、更快和更可靠的机器学习模型
-
分析和理解所选特征
-
探索数据科学竞赛中使用的特征选择技术
要求
-
Python安装
-
Jupyter笔记本安装
-
Python编码技巧
-
Numpy 和 Pandas 的一些经验
-
熟悉机器学习算法
-
熟悉 scikit-learn
描述
欢迎来到机器学习的特征选择,这是在线提供的最全面的特征选择课程。
在本课程中,您将学习如何选择数据集中的变量,并构建更简单、更快速、更可靠且更易于解释的机器学习模型。
本课程适合谁?
您已经迈出了进入数据科学的第一步,您知道最常用的机器学习模型,您可能构建了一些基于线性回归或决策树的模型。您熟悉数据预处理技术,例如删除缺失数据、转换变量、编码分类变量。在这个阶段,您可能已经意识到许多数据集包含大量特征,其中一些特征相同或非常相似,其中一些根本无法预测,而另一些则更难预测。
您想知道如何才能找到最具预测性的特征。哪些可以保留,哪些可以不保留?您还想知道如何以专业的方式编写方法代码。可能您进行了在线搜索,发现周围没有太多关于特征选择的内容。所以你开始怀疑:科技公司是如何做事的?
本课程将帮助你!这是变量选择方面最全面的在线课程。您将学习在全球不同组织和数据科学竞赛中使用的各种特征选择程序,以选择最具预测性的特征。
你会学到什么?
基于科学文章、数据科学竞赛,当然还有我自己作为数据科学家的经验,我收集了一系列很棒的特征选择技术。
具体来说,您将学习:
- 如何去除低方差的特征
- 如何识别冗余特征
- 如何根据统计测试选择特征
- 如何根据模型性能的变化来选择特征
- 如何根据模型赋予的重要性找到预测特征
- 如何以专业的方式优雅地编写程序
- 如何利用现有 Python 库的强大功能进行特征选择
在整个课程中,您将为上述每项任务学习多种技术,您将学习使用 Python、Scikit-learn、pandas 和 mlxtend以优雅、高效和专业的方式实施这些技术。
在课程结束时,您将拥有多种工具来选择和比较不同的特征子集,并确定返回最简单但最具预测性的机器学习模型的特征子集。这将使您能够最大限度地减少将预测模型投入生产的时间。
这个全面的功能选择课程包括大约 70 个讲座,视频时长约 8 小时,所有主题都包括动手实践的 Python 代码示例,您可以将其用作参考和练习,并在您自己的项目中重复使用。
此外,我定期更新课程,以跟上 Python 库的新版本,并在新技术出现时包含它们。
你还在等什么?立即注册,享受特征选择的力量,构建更简单、更快和更可靠的机器学习模型。
本课程适合谁:
- 想要了解如何为机器学习选择变量的初级数据科学家
- 希望提升机器学习特征选择经验的中级数据科学家
- 希望发现特征选择替代方法的高级数据科学家
- 软件工程师和学者转行进入数据科学
- 进入数据科学领域的软件工程师和学者
- 希望提升数据科学技能的数据分析师
课程主题
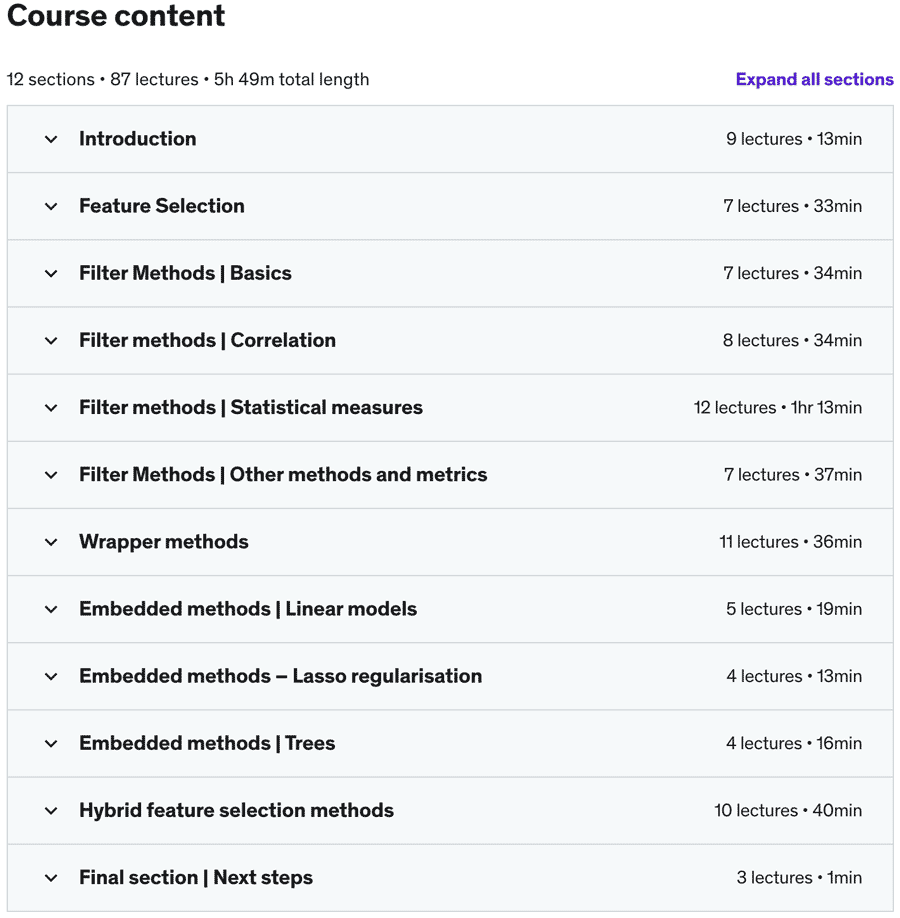
机器学习先决条件的特征选择
Python 安装 Jupyter notebook 安装 Python 编码技巧 一些 Numpy 和 Pandas 经验 熟悉机器学习算法 熟悉 scikit-learn
图片